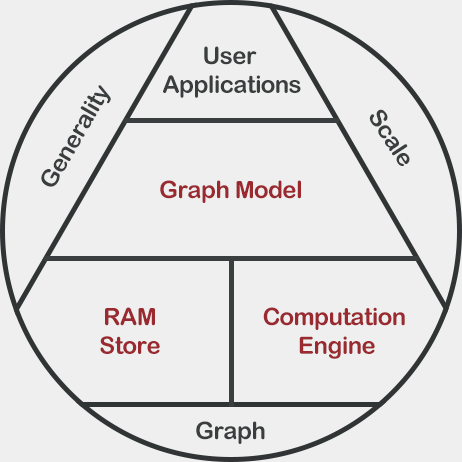
Graph Engine (GE) is a distributed in-memory data processing engine, underpinned by a strongly-typed RAM store and a general distributed computation engine.
The distributed RAM store provides a globally addressable high-performance key-value store over a cluster of machines. Through the RAM store, GE enables the fast random data access power over a large distributed data set.
The capability of fast data exploration and distributed parallel computing makes GE a natural large graph processing platform. GE supports both low-latency online query processing and high-throughput offline analytics on billion-node large graphs.

Schema does matter when we need to process data efficiently. Strongly-typed data modeling is crucial for compact data storage, fast data access, and clear data semantics.
GE is good at managing billions of run-time objects of varied sizes. One byte counts as the number of objects goes large. GE provides fast memory allocation and efficient memory reallocation with high memory utilization ratios.
GE makes use of RAM to speed up the data access as well as the computation. RAM is directly used as run-time storage instead of just being used for serving static resources.
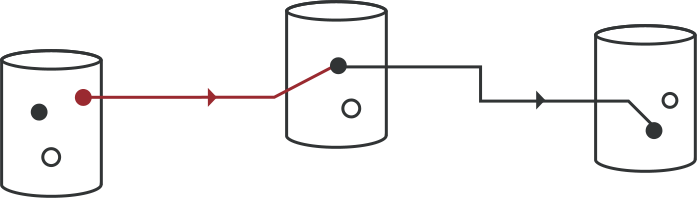
GE is also a flexible computation engine powered by declarative message passing. GE is for you, if you are building a system that needs to perform fine-grained user-specified server-side computation.
From the perspective of graph computation, GE is not a graph system specifically optimized for a certain graph operation. Instead, with its built-in data and computation modeling capability, we can develop graph computation modules with ease. In other words, GE can easily morph into a system supporting a specific graph computation.
GE is a graph data management system. It is designed to manage real-life graphs with rich associated data instead of just graph topology.
On the one hand, it addresses the grand random data access challenge of graph computation at the bottom layer. On the other hand, it addresses the diversity issue of both graph data and graph computation by allowing users to freely specify their own graph models as well as the computation paradigms.